
Real-time voice replacement transforms how video creators tackle multilingual dubbing. Studies show this AI technology reduces traditional dubbing turnaround from weeks to hours, cutting costs by up to 80% while maintaining natural voice quality. If you're managing multilingual video projects or educational content, understanding this technology isn't optional anymore. This guide breaks down exactly how real-time AI voice replacement works, its practical benefits for your workflow, and what you need to know before implementing it in your next project.
Table of Contents
- Introduction To Real-Time Voice Replacement
- Technological Foundations Of Real-Time Voice Replacement AI
- Benefits For Multilingual Video Projects
- Common Misconceptions About AI Voice Replacement
- Comparison With Traditional Dubbing Methods
- Challenges And Limitations Of Real-Time Voice Replacement
- Practical Implementation And Use Cases
- Summary And Future Outlook
- Discover VoixoAI: Your Real-Time AI Voice Replacement Partner
- Frequently Asked Questions
Key takeaways
| Point | Details |
|---|---|
| Real-time voice replacement uses AI to instantly transform and translate video audio within your browser | ASR, neural TTS, and forced alignment work together to deliver natural voice output under 500 milliseconds |
| Creators save 80% on dubbing costs while reaching global audiences faster | Traditional dubbing takes weeks; AI voice replacement delivers results in hours with comparable quality |
| Modern neural TTS achieves over 90% naturalness scores, dispelling robotic voice myths | Advanced systems replicate emotions, accents, and nuanced speech patterns effectively |
| Hardware quality and stable internet directly impact performance | Browser-based processing reduces server delays but requires adequate local resources |
Introduction to real-time voice replacement
Real-time voice replacement is AI technology that instantly transforms original video audio into natural-sounding voices in different languages or styles. Unlike traditional dubbing that requires studio recording and weeks of post-production, this technology processes audio as the video plays, delivering immediate results through your web browser.
The system relies on three core AI components working in harmony. Automatic speech recognition (ASR) extracts spoken words from the original audio track. Neural text-to-speech (TTS) generates new voice audio with natural intonation and rhythm. Forced alignment algorithms ensure the replacement voice syncs perfectly with the speaker's lip movements, maintaining visual coherence.
For video content creators managing multilingual projects, this technology eliminates the traditional dubbing bottleneck. You can localize educational tutorials, marketing videos, or online courses without hiring voice actors or booking studio time. Educators benefit by making learning materials accessible to students speaking different languages, expanding their reach exponentially.
VoixoAI exemplifies this browser-based approach, processing videos from YouTube and Vimeo directly without file uploads. The platform handles voice injection and translation simultaneously, letting creators focus on content rather than technical workflows. This integration streamlines what used to require multiple tools and specialists into a single, accessible solution.
The technology particularly shines for creators producing regular content. Instead of choosing between expensive professional dubbing or poor-quality automated alternatives, real-time voice replacement offers a middle path. You get near-professional quality at a fraction of the cost, with turnaround times measured in hours instead of weeks.
Technological foundations of real-time voice replacement AI
Understanding the AI mechanisms powering voice replacement helps you maximize its potential. The process starts when ASR algorithms analyze the original audio track, converting spoken words into text with contextual understanding. Modern ASR systems recognize multiple languages, accents, and even background noise patterns, extracting clean transcripts in real-time.
Neural TTS then transforms this text into synthetic speech. Unlike older robotic TTS, neural networks trained on thousands of hours of human speech generate voices with natural prosody, emphasis, and emotional coloring. The system adjusts pitch, speed, and tone dynamically based on the content context. A question sounds different from a statement; excitement registers distinctly from calm explanation.
Forced alignment algorithms create the crucial synchronization between new audio and existing video. These algorithms map each phoneme (individual sound unit) in the replacement voice to specific video frames, ensuring lips appear to move naturally with the new speech. Processing delay typically stays under 500 milliseconds for current systems, making the transformation feel instantaneous to viewers.

Browser integration provides a key performance advantage. By processing audio client-side through VoixoAI extensions, the system eliminates server upload delays and bandwidth bottlenecks. Your video data never leaves your device, improving both speed and privacy. The browser's native audio processing capabilities handle the heavy lifting, reducing latency compared to cloud-only solutions.
Here's how these components collaborate in sequence:
- ASR captures and transcribes the original speech in real-time
- Language detection identifies the source language automatically
- Translation engines convert text to the target language if needed
- Neural TTS generates replacement audio with selected voice characteristics
- Forced alignment synchronizes new audio with video timestamps
- Browser audio APIs play the transformed output seamlessly
Pro Tip: Your network speed significantly impacts performance. A stable connection of at least 10 Mbps ensures smooth voice replacement without audio stuttering or delays, especially for longer videos or multiple simultaneous language outputs.
Benefits for multilingual video projects
The time savings alone justify exploring this technology. Traditional dubbing requires scriptwriting, voice actor scheduling, studio booking, recording sessions, and audio engineering. This process typically spans two to four weeks per language. Real-time voice replacement collapses this timeline to hours, letting you publish multilingual versions almost immediately after finalizing your source content.
Cost reductions reach up to 80% compared to professional dubbing services. Voice actors charge per hour or per word, with rates varying by language and expertise. Studio time, audio engineers, and post-production editing add thousands to your budget per project. AI voice replacement operates on subscription models with predictable monthly costs, regardless of how many videos you produce or languages you target.
Viewer retention improves measurably with native-language audio. Research consistently shows audiences engage longer with content in their primary language, even when subtitles are available. Educational content particularly benefits, as students comprehend complex topics more readily when hearing explanations in their native tongue. You expand your addressable audience without diluting content quality or educational effectiveness.

Workflow simplification cannot be overstated. Instead of managing multiple vendors, file versions, and quality checks across languages, you handle everything through VoixoAI in your browser. The platform maintains consistent voice characteristics across all language versions, ensuring your brand identity remains cohesive. Updates to source videos propagate to all language versions quickly, eliminating version control headaches.
Key benefits include:
- Publish multilingual content within hours instead of weeks
- Scale to 10+ languages at the cost of traditional single-language dubbing
- Maintain consistent brand voice across all language versions
- Update content across all languages simultaneously with minimal effort
- Test new markets quickly without major upfront dubbing investments
Common misconceptions about AI voice replacement
The biggest myth persists that AI voices sound mechanical or obviously synthetic. This perception stems from earlier TTS technology that lacked natural prosody. Modern neural TTS models produce voices nearly indistinguishable from human speech with over 90% naturalness scores, rated by both listeners and acoustic analysis. Current systems capture subtle variations in tone, pacing, and emotional coloring that make speech feel genuinely human.
Another misconception claims AI cannot replicate regional accents or emotional expression. In reality, advanced neural networks train on diverse speech samples representing various accents, dialects, and emotional states. The technology successfully modulates voice characteristics to match regional pronunciation patterns, from British English to Australian English to Indian English variations. Emotional speech synthesis captures excitement, concern, authority, and warmth convincingly.
Synchronization quality concerns often surface when discussing real-time systems. People assume rushed processing leads to mismatched audio and lip movements. Forced alignment algorithms have matured significantly, delivering frame-accurate synchronization that maintains visual believability. The technology accounts for different language phoneme counts and speech rhythms, adjusting timing naturally rather than forcing rigid matches.
"The gap between synthetic and human voices has narrowed dramatically. In blind tests, listeners correctly identified AI voices only 55% of the time, barely better than random chance. This technology has crossed the perceptual threshold where quality concerns no longer justify avoiding it for professional applications."
Some creators worry about losing creative control over voice direction and performance nuances. Modern platforms offer extensive customization options for pitch, speed, emphasis patterns, and emotional tone. You adjust these parameters in real-time, previewing results immediately. This iterative control often exceeds what's practical with human voice actors, where re-recording sessions incur significant time and cost penalties.
The myth that AI voice replacement works only for simple, monotone content also crumbles under scrutiny. Educational videos, dramatic narratives, technical explanations, and marketing presentations all benefit from this technology. The key lies in selecting appropriate voice models and tuning parameters to match your content's emotional and informational requirements.
Comparison with traditional dubbing methods
Choosing between AI voice replacement and traditional dubbing depends on your project's specific needs and constraints. Here's a direct comparison:
| Factor | AI Real-Time Voice Replacement | Traditional Human Dubbing |
|---|---|---|
| Turnaround Time | Hours to same day | 2-4 weeks per language |
| Cost per Language | $50-200 monthly subscription | $2,000-10,000 per project |
| Voice Consistency | Perfect consistency across updates | Varies by actor availability |
| Emotional Range | Good; improving rapidly | Excellent; nuanced performance |
| Accent Accuracy | Very good for major dialects | Perfect for native speakers |
| Scalability | Unlimited languages simultaneously | Limited by budget and timeline |
| Update Flexibility | Instant re-processing for edits | Requires new recording sessions |
| Best For | Regular content, multiple languages, quick turnaround | High-stakes productions, dramatic content, unlimited budgets |
Traditional dubbing still excels for cinematic productions, dramatic performances, and content where subtle emotional nuance drives the narrative. Professional voice actors bring interpretive skills that AI hasn't fully replicated, particularly for comedy timing, dramatic pauses, and character voice work.
AI voice replacement dominates for educational content, corporate training, product demos, and regular content publishing. The speed and cost advantages overwhelm minor quality differences for these applications. You can test markets, iterate quickly, and maintain extensive multilingual libraries without prohibitive costs.
Pro Tip: Consider hybrid approaches for optimal results. Use AI voice replacement for 80-90% of your content portfolio, reserving traditional dubbing for flagship projects or brand-defining pieces where absolute top-tier performance justifies the investment. This strategy balances quality, cost, and scalability effectively.
Challenges and limitations of real-time voice replacement
Hardware requirements and internet stability directly impact your experience. Browser-based AI voice processing demands adequate CPU and RAM resources. Older computers or devices with limited memory struggle with real-time audio transformation, causing stuttering or delays. Hardware and connectivity greatly impact latency and audio quality, with systems below recommended specifications producing noticeably degraded results.
Legal and ethical considerations require attention, particularly regarding voice cloning and consent. Some AI voice platforms can replicate specific individual voices from audio samples. Using someone's voice without explicit permission raises legal issues around personality rights and potential misrepresentation. Always secure written consent when cloning identifiable voices, and clearly disclose AI-generated audio in commercial contexts.
Language and dialect limitations persist despite rapid improvements. Less common languages or regional dialects may lack sufficient training data for high-quality output. While major languages like English, Spanish, Mandarin, and French deliver excellent results, minority languages might produce less natural-sounding replacements. Dialect-specific idioms and cultural references sometimes translate awkwardly when processed literally.
Mitigation strategies help you work around these constraints:
- Upgrade hardware to meet recommended specifications before committing to browser-based solutions
- Maintain stable internet connections of 10+ Mbps for smooth processing
- Research voice cloning regulations in your jurisdiction and target markets
- Obtain explicit consent agreements for any identifiable voice replication
- Test output quality for your specific language pairs before large-scale deployment
- Keep human review in your workflow to catch awkward translations or unnatural phrasing
- Use custom pronunciation dictionaries for technical terms or brand names
Background noise in source videos also challenges AI systems. While modern ASR handles moderate noise well, heavily degraded audio with music, crowd sounds, or poor recording quality produces less accurate transcripts. This impacts the downstream voice replacement quality, as errors in transcription propagate through the entire process.
Practical implementation and use cases
Integrating browser-based AI voice replacement into your workflow takes minimal setup. Start by installing the VoixoAI extension in Chrome or Edge. The extension activates automatically when you visit supported video platforms like YouTube or Vimeo. Access settings through the extension icon to configure default languages, voice preferences, and processing options.
Educational content creators use this technology to democratize learning access. A university professor recording lectures in English can instantly offer Spanish, French, Mandarin, and Arabic versions to international students. The same 45-minute lecture that once required weeks of professional dubbing per language now processes in under an hour for all four versions simultaneously.
Multilingual marketing teams leverage real-time voice replacement to test campaigns across regions quickly. Instead of committing to expensive dubbing before knowing which markets respond best, they generate test versions in 10 languages within a day. Performance data guides where to invest in premium localization later. This agile approach reduces risk while maximizing market exploration.
Corporate training departments benefit significantly. Compliance training, safety procedures, and onboarding content require frequent updates as regulations change or processes evolve. AI voice replacement lets training teams update source content once and regenerate all language versions immediately. Consistency improves while costs plummet compared to re-recording dozens of language versions every quarter.
Implementation steps:
- Install the browser extension and create an account
- Upload or navigate to your video content on supported platforms
- Select target languages and voice characteristics through the extension interface
- Preview the replacement audio to verify quality and synchronization
- Adjust voice parameters like speed, pitch, and emphasis as needed
- Process the full video and download or share the multilingual versions
Pro Tip: Start with subtle voice customizations rather than extreme adjustments. Slight pitch or speed changes often suffice for matching target audience expectations. Over-customization can produce unnatural-sounding speech that breaks immersion. Test with small audience samples before rolling out extensively modified voice parameters.
Summary and future outlook
Real-time AI voice replacement has matured from experimental technology to practical production tool. The combination of fast turnaround, significant cost savings, and increasingly natural voice quality makes it indispensable for creators managing multilingual video content. While traditional dubbing retains advantages for premium dramatic productions, AI solutions dominate for educational, corporate, and regular content publishing.
Key limitations around hardware requirements, language coverage, and legal considerations require thoughtful navigation. These challenges diminish as technology improves and regulatory frameworks mature. Current systems already deliver professional-grade results for most applications when implemented properly.
Emerging trends point toward even more impressive capabilities. Emotional intelligence in voice synthesis continues improving, with systems detecting and replicating increasingly subtle emotional states. Real-time accent adaptation will let single voice models convincingly speak dozens of regional variations. Integration with video editing platforms will streamline workflows further, eliminating the need to switch between multiple tools.
The technology's global impact on content accessibility cannot be overstated. Small creators and educators now wield localization capabilities previously reserved for major studios with massive budgets. This democratization accelerates knowledge sharing across language barriers, making quality educational content universally accessible regardless of viewer location or language background.
Discover VoixoAI: your real-time AI voice replacement partner
Ready to transform your multilingual video workflow? VoixoAI brings everything covered in this guide directly to your browser. The platform's AI-powered extension works seamlessly with YouTube and Vimeo, processing videos without uploads or file transfers.
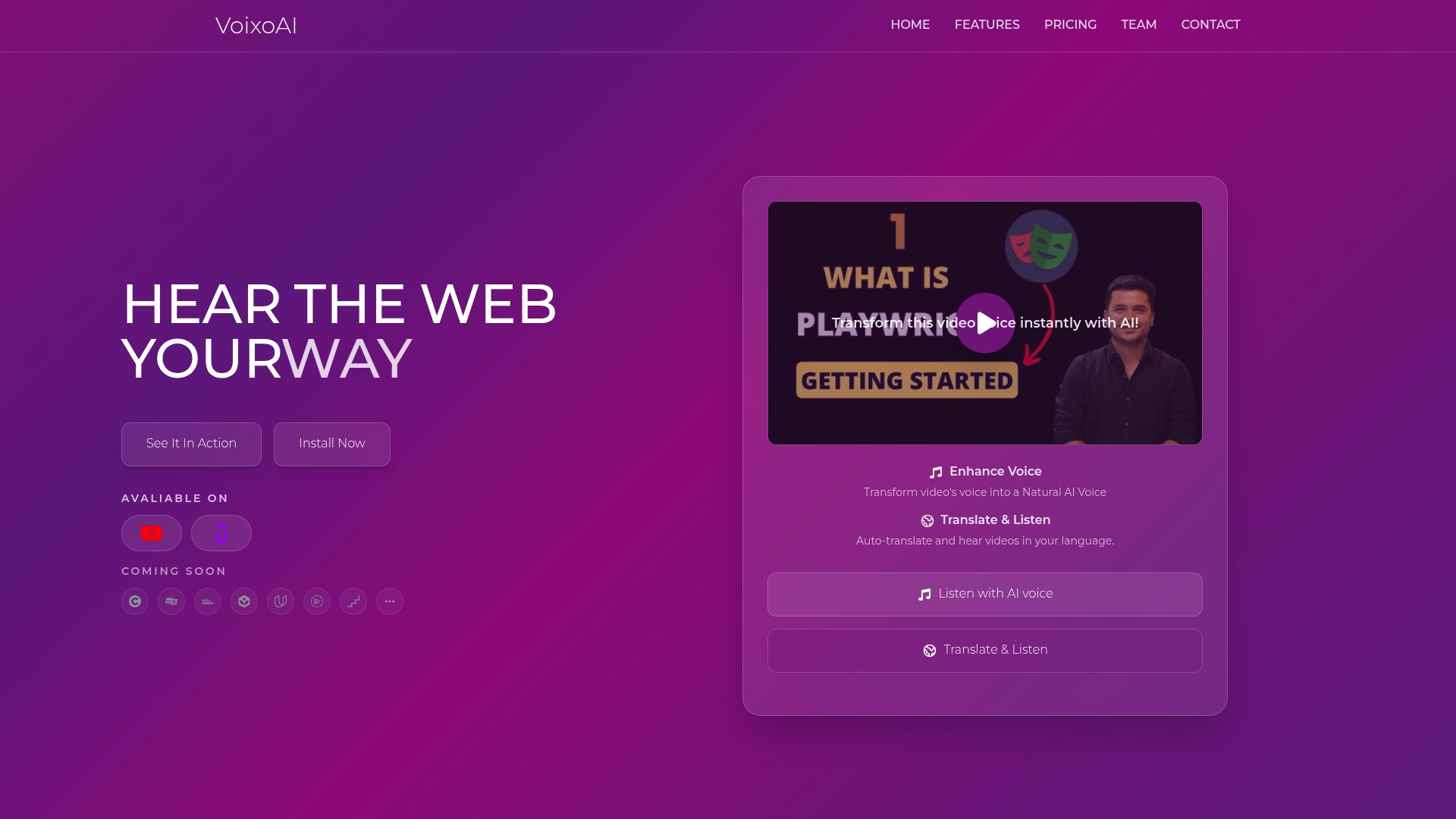
Customize voice characteristics including tone, pitch, accent, gender, and speed to match your audience perfectly. The high-fidelity synthesis produces natural, expressive voices that maintain viewer engagement across languages. Whether you're creating educational content, marketing videos, or corporate training, VoixoAI simplifies the entire dubbing process into clicks instead of weeks of coordination. Flexible subscription plans scale with your needs, from testing new markets to managing extensive multilingual content libraries.
Frequently asked questions
What is real-time voice replacement?
Real-time voice replacement is AI technology that instantly transforms video audio into different voices or languages as the video plays. The system uses automatic speech recognition, neural text-to-speech synthesis, and forced alignment algorithms to replace original voices with natural-sounding alternatives in under 500 milliseconds.
How does real-time voice replacement improve multilingual video production?
It reduces dubbing turnaround from weeks to hours while cutting costs by up to 80% compared to traditional methods. Creators can publish content in multiple languages simultaneously without managing voice actors, studios, or complex post-production workflows. The technology maintains consistent voice quality across all language versions and allows instant updates when source content changes.
Can AI voice replacement capture natural emotions and accents?
Yes, modern neural TTS models achieve over 90% naturalness scores in blind listener tests. Advanced systems successfully replicate regional accents, emotional expressions, and nuanced speech patterns. The technology adjusts prosody, emphasis, and tone dynamically based on content context, producing voices that feel genuinely human rather than robotic.
What are the main challenges when using real-time voice replacement?
Hardware and internet stability significantly impact performance, with systems requiring adequate CPU, RAM, and 10+ Mbps connections for smooth processing. Legal considerations around voice cloning require explicit consent when replicating identifiable voices. Less common languages or dialects may produce lower-quality output due to limited training data, and background noise in source videos can reduce accuracy.